FreeRTOS
信息安全
django
自定义气泡提示框
缩位求和
WS2812驱动程序
matplotlib
vim
Shell脚本
BeanMap
驱动开发
picgo
高校就业管理
就业管理系统
diffusion model
扩散模型
华为云应用魔方
AI绘画 神经网络
关联数组
毛球修剪器方案
反爬虫
2024/4/12 11:41:02
爬虫与反爬虫(斗智斗勇)
一、爬与反爬
爬虫目的:
1.获取数据。填充公司的数据库,可以用来做数据测试。也可以直接登录
2.通过爬虫爬取大量的数据。用来制作搜索引擎
3.通过爬虫爬取数据,做数据采集和数据分析的工作
4.通过爬虫爬取数据,用于做训练模…

Python进阶 │反爬虫和怎样反反爬虫
爬虫、反爬虫和反反爬虫是网络爬虫工作过程中一直伴随的问题。 在现实生活中,网络爬虫的程序并不像之前介绍的爬取博客那么简单,运行效果不如意者十有八九。首先需要理解一下“反爬虫”这个概念,其实就是“反对爬虫”。根据网络上的定义&…
Python爬虫防封杀方法集合
Python 2.7 IDE Pycharm 5.0.3 前言
在爬取的过程中难免发生ip被封和403错误等等,这都是网站检测出你是爬虫而进行反爬措施,这里自己总结下如何避免方法1:设置等待时间
有一些网站的防范措施可能会因为你快速提交表单而把你当做机器人爬虫…

网易云反爬虫,中国新说唱
这篇文章是之前在公众号写的
登录https://music.163.com/ 网易云音乐搜索新说唱,打开Chrome的开发工具工具选择Network并重新加载页面,找到与评论数据相关的请求即name为
web?csrf_token的POST请求,如下图所示 查看该请求的headers我们发…

抵御爬虫的前线护盾:深度解读验证码技术的演变历程
一.前言
在当今信息技术迅速发展的背景下,网站和在线服务面临着日益增长的自动化访问威胁,这些大多来自于各类爬虫程序。这种大量的自动化访问不仅对网站的正常运行构成压力,还可能导致敏感数据的泄露,甚至被用于不正当竞争和恶意…
关于反反爬虫技术:对限制连续请求时间的处理
一般的反爬措施是在多次请求之间增加随机的间隔时间,即设置一定的延时。但如果请求后存在缓存,就可以省略设置延迟,这样一定程度地缩短了爬虫程序的耗时。
下面利用requests_cache实现模拟浏览器缓存行为来访问网站,具体逻辑如下…
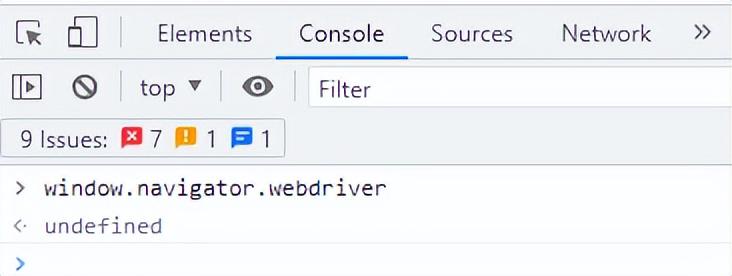
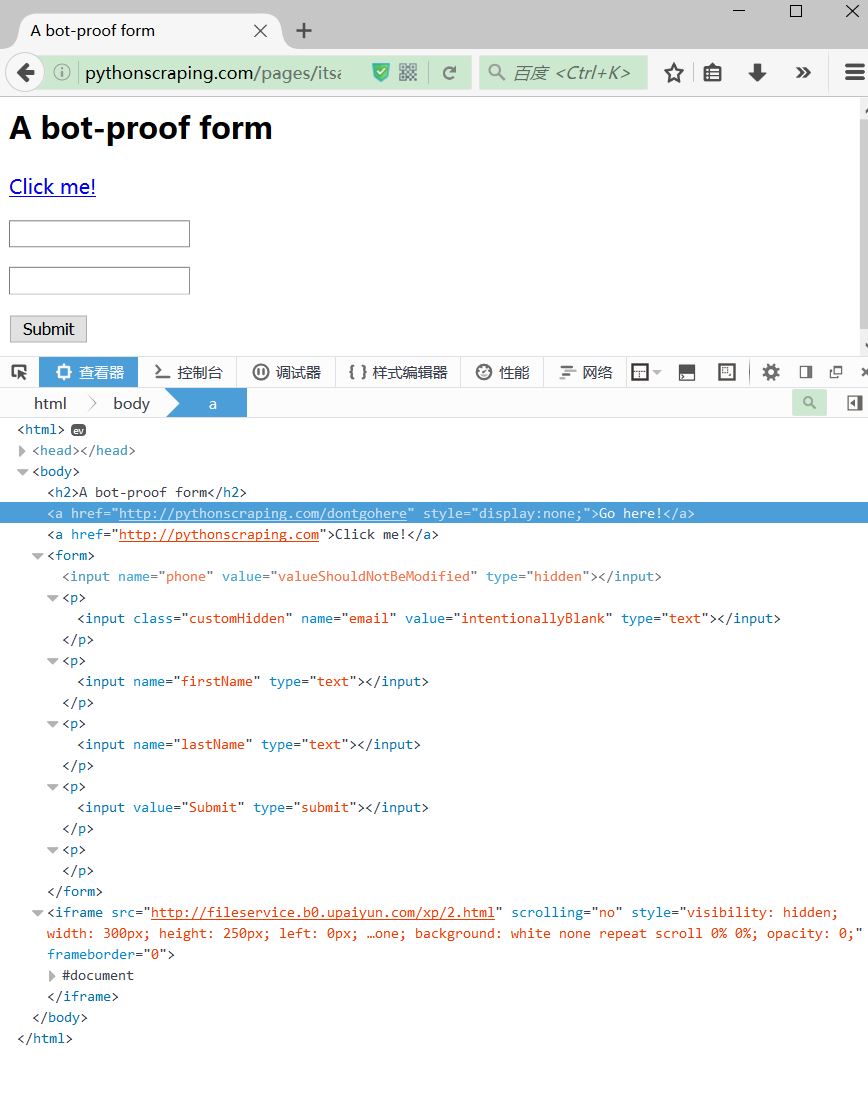
2023爬虫学习笔记 -- selenium反爬虫操作(window.navigator.webdriver属性值)
一、无可视化浏览器操作1、导入需要的函数,固定写法,并设置相关浏览器参数from selenium.webdriver.chrome.options import Options浏览器设置Options()
浏览器设置.add_argument("--headless")
浏览器设置.add_argument("--disable-gpu&…

猿人学爬虫攻防大赛 | 第二题: js 混淆 - 动态Cookie
猿人学爬虫攻防大赛 | 第二题: js 混淆 - 动态Cookie
开局直接F12,由于题目都说好是动态Cookie了,我们直接看Cookie,第一个请求中没有set-cookie,第二个请求中的Cookie就产生了一个m593289d3022cb6f1d4ebb3075d836f7f|1606978187…
常见的反爬虫风控 | 验证码风控
一.前言
在当今信息技术迅速发展的背景下,网站和在线服务面临着日益增长的自动化访问威胁,这些大多来自于各类爬虫程序。这种大量的自动化访问不仅对网站的正常运行构成压力,还可能导致敏感数据的泄露,甚至被用于不正当竞争和恶意…

“反爬虫”与“反反爬虫”
反爬虫:
不返回网页:如不返回内容和延迟网页返回时间返回数据非目标网页:如返回错误页、返回空白页和爬取多页时均返回同一页增加获取数据的难度,:如登陆才可查看和登陆时设置验证码
不返回网页
爬虫发送请求给相应…
How to implement anti-crawler strategies to protect site data
How to implement anti-crawler strategies to protect site data 信息校验型反爬虫User-Agent反爬虫Cookie反爬虫签名验证反爬虫WebSocket握手验证反爬虫WebSocket消息校验反爬虫WebSocket Ping反爬虫 动态渲染反爬虫文本混淆反爬虫图片伪装反爬虫CSS偏移反爬虫SVG映射反爬虫字…